



In 2026, facial recognition has become a silent but constant presence in our daily lives: it unlocks phones in a second, lets passengers breeze through airport security without showing documents, authorizes payments with a simple glance, and in many contexts monitors public spaces. Yet most people have a very simplified idea of how this technology actually works. They imagine a camera snapping an image and comparing it against a database of faces, like something out of a science-fiction movie. The reality is far more sophisticated, mathematical, and in some respects surprising. To truly understand what happens when a facial recognition system “sees” a person, one must follow step by step the long journey that transforms a face into a verified identity.


How Facial Scanners Really Work: The Technology Behind Visual Recognition
Everything begins with the detection phase. When a camera or sensor frames a scene, the system must first determine whether and where a face is present. This is no simple task: the face may be partially covered, poorly lit, angled dramatically, or in motion. Modern algorithms, based on increasingly sophisticated convolutional neural networks, can draw a virtual box around a face even under difficult conditions, and they do so in just a few milliseconds.
Once the face is isolated, the more delicate work begins: landmark mapping. The system identifies dozens or hundreds of key points, the corners of the eyes, the pupils, the tip of the nose, the contour of the lips, the cheekbones, the line of the jaw, and uses them to calculate distances, angles, curvatures, and geometric ratios. In the most advanced systems, which use depth sensors or structured light, a third dimension is added: the face is reconstructed in 3D, capturing micro-contours and skin textures that are unique to each individual.
From these raw data, what experts call a “feature vector” or embedding is extracted: a numerical vector with hundreds of dimensions that represents the face in an abstract mathematical space. This embedding is no longer an image but an encrypted mathematical signature. It is here that the true magic of artificial intelligence takes place: deep learning models, trained on millions of faces, transform these characteristics into a biometric template that can be compared with other templates with extraordinary speed and precision.
During authentication, the system compares the new embedding with the one previously stored using similarity metrics; if the distance between the two vectors falls below a certain threshold, the identity is confirmed.
The entire process in a modern 2026 system takes less than three hundred milliseconds and achieves accuracy above 99.5% under controlled conditions. But the real strength of this technology lies not only in its speed or precision: it lies in the fact that the original photo of the face is never stored—only its anonymous mathematical template, drastically reducing privacy risks.

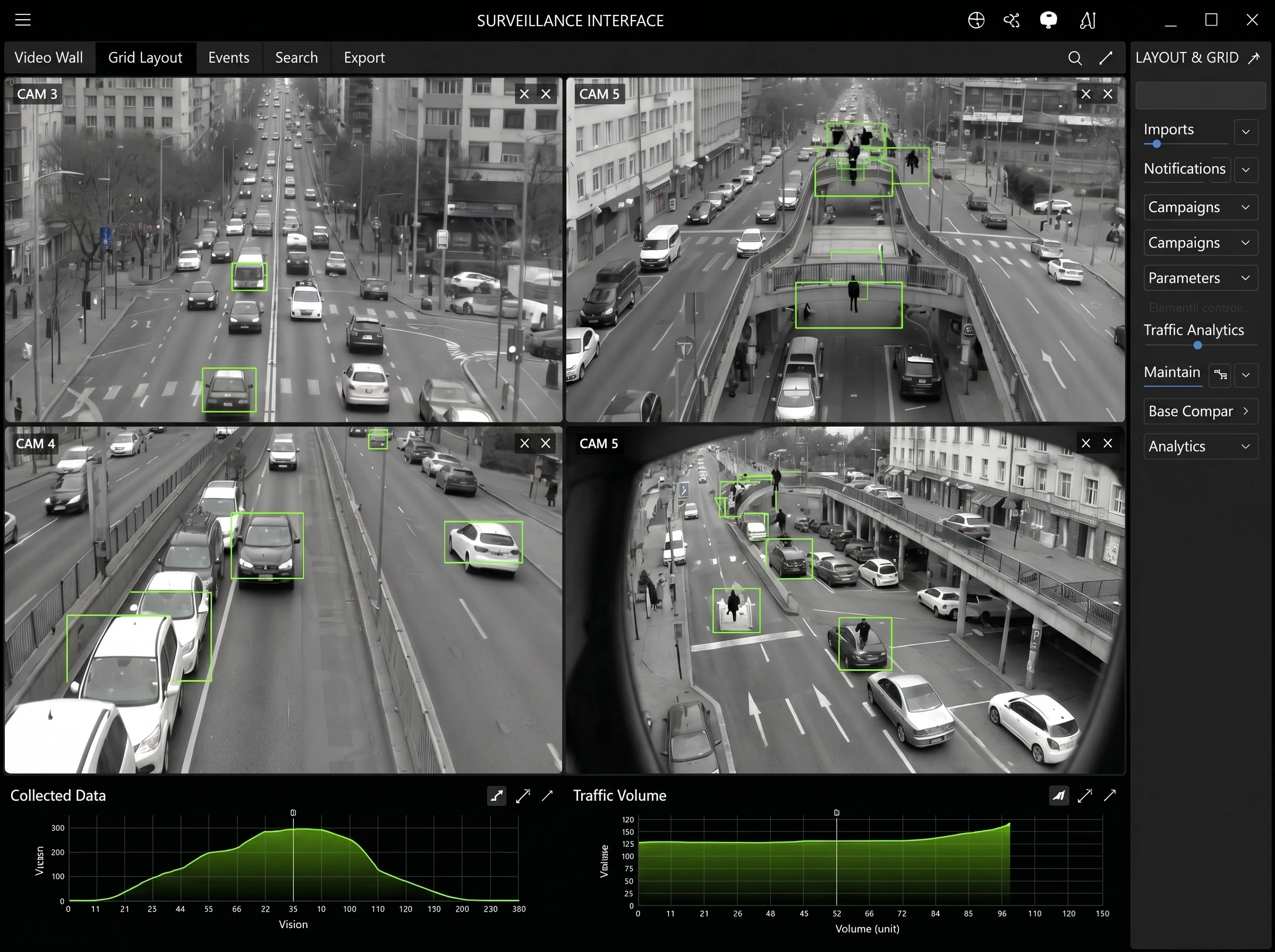
Visual Tracking and Surveillance Systems: From the Individual to Smart Cities
While individual authentication, the kind we use to unlock our phones or access our bank accounts, is the most visible form of facial recognition, the true social and political impact of this technology emerges when it is scaled to the mass level. In major transit hubs, shopping centers, stadiums, and especially so-called smart cities, systems do not merely verify a known identity: they perform large-scale searches, comparing every detected face against databases containing millions of people. This shift from “one-to-one” to “one-to-many” radically changes the nature of the system and raises profound questions.
Imagine walking through an airport. The cameras do not recognize you because you previously registered your face: they recognize you because your embedding is compared in real time against watchlists or a massive database of passengers. When the system finds a sufficiently close match, it triggers an alert and begins tracking your movements across multiple cameras, even as you change angle, lighting, or partially obscure your face. This re-identification capability, made possible by temporal embeddings that incorporate movement over time, is what makes visual surveillance systems so powerful, and so controversial. In 2026, many cities are integrating these technologies into “urban intelligence” platforms, promising reduced crime, more efficient traffic management, and prevention of attacks. Yet the same technology that can locate a missing person in minutes can also be used to monitor anyone’s movements at any time, without that person’s awareness.
China has emerged as the global leader in scaling these technologies, having built one of the world’s most extensive facial recognition networks and integrated it deeply into its smart city infrastructures and public security systems.
One of the most significant developments of the past two years has been the shift toward edge computing. Instead of sending all video streams to centralized servers, processing now occurs directly on the sensors or local gateways. Only the embeddings, which are anonymous by nature, or alerts are transmitted.
This reduces bandwidth requirements, lowers latency, and above all drastically decreases the risk of sensitive data breaches. Containerized solutions can now run on edge devices with very low power consumption, making widespread yet technically more privacy-respecting surveillance possible. Still, the fundamental question remains: who controls these systems? Who decides which faces end up on watchlists? And what guarantees do we have that the data will not be used for purposes other than those declared?

Security, Vulnerabilities, and Countermeasures: Liveness Detection and the War on Deepfakes
No facial recognition system can be considered secure if it cannot distinguish a living face from a reproduction of one. This is the greatest challenge the technology faces in 2026, and the ongoing battle between attackers and defenders has become a genuine technological arms race.
Threats fall into two main categories. On one side are presentation attacks: high-resolution printed photos, smartphone screens replaying videos, or 3D masks in silicone or latex created with the latest generation of printers. On the other, and increasingly dangerous, are digital attacks: deepfakes generated in real time and injected directly into the system’s video stream. In 2025 and 2026 these attacks have reached such a level of realism that they can deceive even attentive human observers, and estimates suggest that by 2027 more than a billion mobile devices will be targeted by fraud attempts based on synthetic identities.
To counter these threats, liveness detection has emerged and evolved, the system’s ability to verify that the presented face belongs to a living person actually present at that moment. Techniques are divided into active and passive.
Active methods require explicit user cooperation, blinking, smiling, or moving the head according to randomly generated instructions, and are still widely used in high-risk contexts such as bank onboarding. Passive methods are completely transparent to the user and analyze a series of involuntary signals: the face’s natural micro-movements, blood flow causing imperceptible color variations in the skin, the three-dimensional texture of the skin itself, the perspective distortion created when the device approaches the face, and even behavioral patterns such as how the phone is held. In 2026, the most advanced solutions, such as those from Paravision, Facia, and FaceTec, achieve attack detection rates above 99% with false positive rates below 0.1%, according to independent tests by accredited laboratories.
Paradoxically, generative artificial intelligence, the same technology that makes the most dangerous deepfakes possible, is now also being used in defense. Anomaly detection models trained on millions of real and synthetic videos can identify artifacts invisible to the human eye: inconsistencies in blinking patterns, unnatural micro-expressions, incoherent lighting between face and background, or compression artifacts typical of generated videos.
In 2026 several companies offer real-time deepfake detection solutions that exceed 95% accuracy on public datasets, and these technologies are being integrated directly into next-generation liveness detection systems. The war is far from won, but the gap between attack and defense is steadily narrowing thanks to this race for innovation.


The Future of Visual Biometric Parameters: Forecasts, Scenarios, and Ethical Questions (2026–2035)
To understand where this technology is heading, it is useful to look at the most established trends that emerged in industry reports from 2025 and 2026, together with the research directions indicated by bodies such as NIST and the leading companies in the sector.
The trajectory of visual biometric systems over the next ten years appears dominated by three major converging forces: multimodality, continuity, and governance. By 2028–2029 the vast majority of facial authentication systems will no longer operate in isolation but as components of multimodal ecosystems that combine face, voice, behavior, how the device is held, typing patterns, micro-movements, contextual signals such as GPS location, Wi-Fi network, and time of day, and even environmental data such as brightness and background noise. This approach will drastically reduce both false positives and spoofing risks, making authentication far more robust and difficult to circumvent.
The second major shift will be the move from point-in-time authentication to continuous authentication. Instead of verifying identity only at login or access, systems will begin monitoring biometric and behavioral patterns in the background, intervening only when the risk level rises above a dynamic threshold. This model, already successfully tested in enterprise environments, is expected to become mainstream in the consumer segment by 2030, offering a better balance between security and seamless user experience. The third force, perhaps the most decisive in the long term, will be governance. 2026 marks the beginning of a phase in which regulators, from the European Union with the AI Act to updated NIST guidelines in the United States, will impose increasingly stringent requirements for explainability, auditability, and data minimization. Biometric templates will gradually become more portable and directly controlled by the user, while processing will increasingly move to the edge and personal devices, in line with privacy-by-design principles.
However, the greatest risk will not be purely technological but social and political: the normalization of mass biometric surveillance. If clear limits are not imposed on its use in public spaces and for generalized surveillance purposes, we risk entering an era in which every citizen is trackable in real time without full awareness. The most desirable scenario is one in which, by 2032, a new equilibrium emerges: widespread visual biometrics for high-value services, payments, physical access, digital identity, accompanied by strong regulatory protections, explicit consent, and simple mechanisms for immediate revocation. The most concerning scenario, by contrast, is one of “soft surveillance” in which citizens passively accept the progressive loss of anonymity in exchange for convenience and perceived security, without real guarantees over the control of their own data.
Alongside this main trajectory, at least three alternative scenarios deserve attention. The first is possible regulatory fragmentation: the European Union, the United States, and China could end up developing incompatible standards and requirements, creating separate biometric ecosystems that complicate life for citizens and businesses operating globally. The second scenario involves a kind of “biometric fatigue”: faced with recurring scandals over data security and documented cases of abuse, a significant portion of the public might reject biometric authentication for the most sensitive operations, returning to traditional methods or systems based on physical possession. The third scenario, perhaps the most destabilizing, envisions a sudden acceleration in attackers’ capabilities: if generative models reach a point where deepfakes become indistinguishable from reality even to the most advanced detection systems, the entire security architecture based on faces could enter a phase of profound crisis.
Each of these scenarios raises ethical questions that can no longer be avoided. Who truly owns our biometric data?
How can the convenience of a passwordless world be reconciled with the fundamental right to anonymity? And what is the acceptable limit between collective security and individual freedom in an era in which every face can become a real-time trackable identity?
The answer does not lie solely in technology, however sophisticated it becomes. It lies in the ability to build a regulatory and cultural framework that places the individual at the center, guarantees transparency, control, and the possibility of revocation, and prevents convenience from becoming the pretext for pervasive and silent surveillance.
In 2026 we are still in time to steer this choice.
The question is whether we will be farsighted enough to make the right one.
Bibliography:
The New York Times – “At Check-In, Your Face Is Increasingly Your ID” (January 2026)
Wired – “Metalenz Has Figured Out a Way to Make Face ID Invisible” (May 2026)
MIT Technology Review – “How LLMs could supercharge mass surveillance in the US” (April 2026)
The Guardian – “How ICE is using facial recognition in Minnesota” (January 2026)









